

把一台能运行 122B 大模型的 AI 主机塞进口袋,需要付出什么代价?
过去大半年,端侧 AI 硬件的逻辑正在发生变化。
两个月前,国内掀起一场现象级的本地部署 Agent 热潮,大量 AI 爱好者开始“养虾”,让原本偏小众的 Mac mini 意外出圈,一度出现溢价和缺货。在更硬核的开发者圈子里,三四万元的英伟达 DGX Spark 同样热度不低,因为它已经能够在本地运行千亿参数模型。
Mac mini 和 DGX Spark 同时走红,背后其实指向的是同一个趋势:Agent 正在迅速抬高端侧 AI 硬件的门槛。
此前,40TOPS 级别的 AI PC,仅能完成对话、生成等轻量任务。但进入 Agent 时代后,开发者开始追求更大的模型、更长时间的本地推理,以及真正能够承担生产力任务的端侧 AI 设备。
问题随之出现。Mac mini 足够安静、低功耗,却很难支撑更大的本地模型;DGX Spark 拥有强悍性能,但价格、功耗与散热,又很难真正走向大众化。大算力、低功耗与小体积之间,似乎始终难以兼得。
Agent 时代真正缺少的,不再只是一台更强的 AI PC,而是一种能够 7 × 24 小时运行、低功耗、安静,并具备本地执行能力的新终端。
一种介于 AI PC 与 AI 工作站之间的 Agent Computer 出现了。最近发布的联想 AI 主机 P7,仅 300 克、30W 功耗的设备,拥有 190TOPS 端侧 AI 算力,能在本地运行 122B 参数模型。
AI 2.0 时代,需要怎样的 Agent Computer?
传统 AI 更多还是一问一答式交互,任务结束后,模型也随之停止运行。但 Agent 不同,它需要长期在线、持续调用模型、自主拆解任务,并在本地完成记忆、推理、执行等一整套过程。
这意味着 Agent 设备比拼的,不再只是瞬时性能,而是长期稳定运行能力。
换句话说,AI 2.0 时代真正需要的不是 AI PC 的简单升级版,而是一种介于 AI PC 与 AI 工作站之间的新终端,它既要具备运行大模型的能力,又必须兼顾低功耗、静音、小体积,以及 7 × 24 小时持续工作的稳定性。
联想 AI 主机 P7,正是在 AI 2.0 需求下诞生的 Agent Computer 新物种。它既尝试接近 DGX Spark 的大模型生产力能力,又保留了类似 Mac mini 的低功耗与静音特性。
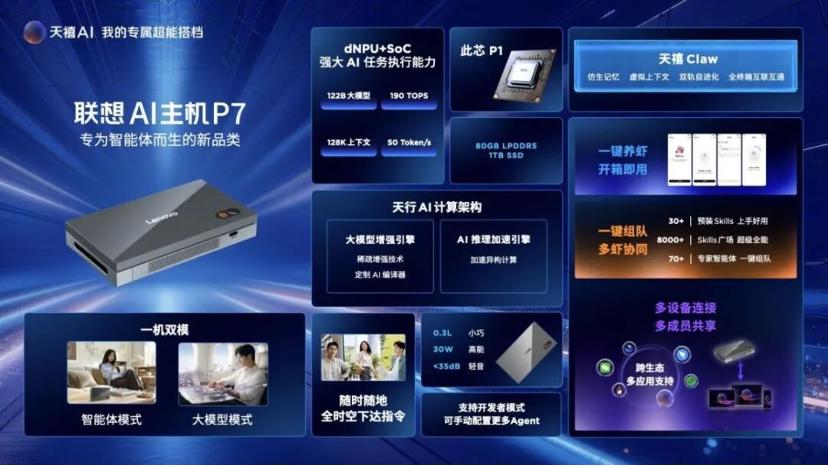
P7 拥有 190TOPS 异构 AI 算力(dNPU+SoC),其中 160TOPS 来自后摩漫界 M50 dNPU,30TOPS 来自此芯 P1 SoC。整机最高支持 122B 参数模型本地部署,最高可配置 80GB RAM,并支持 128K 上下文窗口。
在无网环境下,P7 本地自主推理速度最高可达 50 Tokens/s,可以实现 7 × 24 小时连续执行 Agent 任务。
围绕 Agent 长期在线需求,P7 的机身只有手掌大小,重量约 300 克,甚至可以直接通过充电宝供电运行。为了在小体积下实现持续稳定运行,P7 还将整机功耗控制在 30W 以内,并将运行噪音压低至 35 分贝以下。
这意味着,联想 AI 主机 P7 已经开始真正具备本地生产力价值。
更重要的是,与传统 PC+AI 的思路不同,P7 并不是在原有设备中增加 AI 功能,而是围绕 Agent 场景重新定义终端逻辑。
例如,P7 采用了一机双模设计,在智能体模式下,本地运行天禧 Claw,将复杂任务尽可能留在本地执行;在大模型模式下,则通过开放 API Key 接入各类 AI 应用与智能体,直接承担本地推理与 Token 生成能力。
P7 的推出代表着过去只有高功耗工作站才能承担的大模型本地推理能力,开始有机会进入更低功耗、更低成本的小型设备。
而只有当大模型推理能够在低功耗、小体积条件下长期运行,Agent 才有可能真正从少数开发者设备,逐渐走向更广泛的消费级与行业终端场景。
支撑这种 Agent Computer 形态成立的,是 P7 背后一套不同于传统 GPU 路线的新算力方案。
千亿模型装进口袋之后,算力逻辑也变了
联想在 P7 立项初期就已经明确,要做一台能放进口袋、又能本地运行大模型的 AI 主机。这意味着它的芯片必须同时满足三个几乎互斥的条件:大算力、低功耗、小体积。
传统 AI 芯片很难同时兼顾这些需求,核心在于数据搬运——计算单元与存储单元物理分离,数据在两者之间频繁流动,带来额外的能耗与延迟。
AI 芯片行业因此不断探索新的架构路径,其中一个正在被越来越多厂商探索的方向就是存算一体,存算一体让数据在存储侧就近完成计算,从而减少搬运开销,提升整体能效。
联想选择引入存算一体架构芯片,作为 P7 的主要 AI 算力来源,也就是 dNPU(Discrete NPU),它类似于独立 GPU 的定位,拥有更强的 AI 性能。
这颗 dNPU,正是后摩智能在 2025 年推出的存算一体 AI 芯片——后摩漫界 M50。
后摩漫界 M50 采用存算一体架构设计,具备 160TOPS 物理算力,配备最高 48GB 内存与 153.6GB/s 带宽,典型功耗仅 10W,能效达到传统架构芯片的 5~10 倍。

雷峰网了解到,M50 在设计阶段就针对大模型部署进行了优化,通过 SRAM 与 48GB LPDDR5 的组合方案,在兼顾性能的同时,提升了千亿参数模型的可部署性与成本可控性。
真正的挑战不止于芯片,而是如何让千亿参数模型在一台 300 克级别的设备上长期稳定运行。这需要联想与后摩智能在本地 Agent 系统、推理框架以及软硬件协同层面进行深度配合。
尤其是在 Agent 执行链路、模型调度与端侧资源管理上,联想需要一套全新的系统能力来支撑持续运行的 AI 任务。
从 2025 年下半年项目正式启动开始,联想与后摩智能组建联合团队,围绕硬件设计、软件适配与推理框架展开了长达十多个月的联合攻坚,最终实现了在后摩漫界 M50 上运行千亿参数大模型。
目前,P7 已经支持千问、智谱、DeepSeek 等主流模型,并可实现新模型的 Day0 适配,即模型发布当天即可完成运行支持。对于用户而言,这使得 P7 不再只是演示型设备,而是一台可长期运行 Agent 任务的本地 AI 终端。
从芯片到系统,再到 Agent 执行能力,联想与后摩智能正在共同验证一种新的 AI 主机形态。
随着端侧大模型持续演进,这种兼顾性能、功耗与长期运行能力的 Agent Computer,正在成为 AI 2.0 时代最具现实落地潜力的终端方向之一。
Agent 浪潮重构硬件规则,存算一体迎来推理黄金时代
AI 芯片的竞争逻辑,正在发生一场静默的翻转。
过去几年,行业的核心指标是峰值算力,比拼的是谁能训练更大的模型,GPU 也因此成为整个 AI 时代的核心基础设施。
但当 AI 从 1.0 时代的生成一次回答走向 2.0 时代的长期运行、持续执行任务的 Agent 形态后,芯片的评价体系开始变化:能效比、持续推理能力、本地执行复杂任务的稳定性,逐渐与峰值算力同等重要。
这一变化并不是传统 AI 芯片的优势所在,却为新的架构路径打开了窗口。
一个明显的信号来自行业巨头。英伟达重金收购初创公司 Groq 核心技术资产,将其 LPU (Language Processing Unit)语言处理单元用于高性能推理场景。后摩智能与 Groq 都是存算一体技术路线,都是基于 SRAM 设计产品,减少数据搬运、提升推理能效,只是产品叫法不同。
后摩智能在成立之初就专注于存算一体技术的研发与产业化,2024 年推出针对大模型推理优化的后摩漫界 M30,支持运行 60 亿参数模型,并获得了中国移动等客户。
目前,基于后摩漫界 M50,后摩智能已经搭建起 M.2 卡、DM.2 卡、Pcie 卡,最高 640TOPS 算力的完整产品矩阵,并完成了从技术原型到规模化商用的关键跨越。如今后摩漫界 M50 已全面落地联想 AI 主机 P7、 AI PC、桌面机器人、Agent Box、智能语音终端、AI 网关等多元端边场景。
后摩智能也在研发下一代芯片,目标是进一步提升能效比与大模型推理能力,以适配未来更复杂的 Agent 时代。
这是一个标志性的转折点,GPU 定义了大模型训练时代,而 Agent 的全面爆发,正将算力竞争从云端训练中心,推向海量的端侧、边缘推理节点。在这场算力格局迁移中,以存算一体为代表的 AI 原生架构,不再只是 GPU 的补充或替代,更在逐步建立端侧 Agent 时代的全新硬件标准。
随着 Agent 开始向更多本地设备渗透,行业对于低功耗、高能效端边推理芯片的需求也会持续增加。
未来,围绕端侧大模型推理,还会出现更多新的芯片形态与架构路线。
在这场 Agent 驱动的 AI 硬件范式切换中,AI 原生的芯片成为竞争的关键,像后摩智能这样率先完成存算一体商业化落地的公司,正在进入更大的增长通道。
 晋ICP备17002471号-6
晋ICP备17002471号-6

 分享给我的好友
分享给我的好友