
太贵了。
时值美国圣诞购物季,喜欢电子产品的朋友们,却发现了这样恐怖的景象:
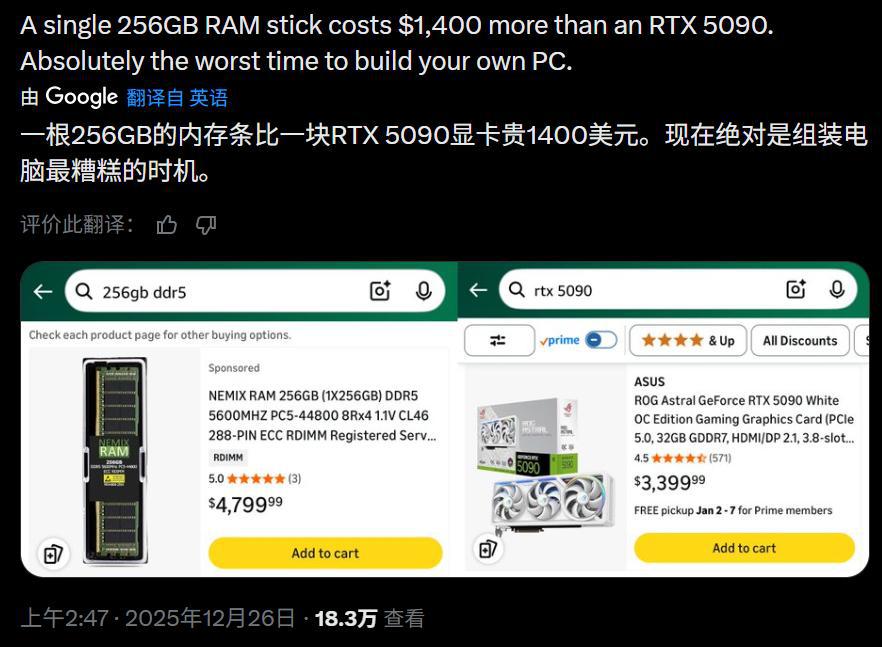
英伟达的顶配 GPU RTX 5090 官方起售价为 1999 美元(经过市场溢价可能达到了 3000 美元以上),而一根单条 256GB 的 DDR5 内存如今的市场价却也飙升到了 3500-5000 美元之间。
电脑内存,这个长期以来在配置里不占大头的组件,现在的价格已经涨到了令人乍舌的程度,这在个人消费领域已经成了个荒诞但又现实的写照。而且根据各种新闻,短期看来 PC 内存还要继续涨价,手机据说也要涨价。
这一波内存涨价的根本原因在于:产能都被 AI 截胡了,目前的内存市场正处于一场由 AI 算力需求引发的「结构性紧缺」中。
AI 训练与推理能力取决于 GPU、TPU 以及数据中心的整体性能,而 GPU / TPU 需要 HBM,AI 数据中心需要 LPDDR 内存。全球只有三家公司具备生产高端 HBM 与 LPDDR 的能力:SK 海力士、三星电子、美光。
今年 10 月,OpenAI 以「星际之门」项目的名义,与三星和 SK 海力士签下协议,锁定了每月高达 90 万片 DRAM 晶圆供应(HBM 本质上就是将多层 DRAM 芯片垂直堆叠在一起),这相当于全球 DRAM 月产量的 40%。这种规模的采购,瞬间抽走了大量本可用于消费市场的产能,直接导致合约价在交易公布后跳涨。
内存厂家的产能是存在上限的。由于 AI 服务器对内存的出价极高(向英伟达出售 HBM 内存的利润是向消费者出售 DDR5 内存的 5 倍),厂家会优先将生产线分配给大客户。这直接导致了供应给 PC 市场的常规 DDR5 晶圆减少,从而引发全球性的普涨。
不单单是内存,AI 着实是电脑配件价格上涨的强力驱动力。
不仅是 AI 基础设施的内存,现在「AI PC」的概念也要求更大的内存来运行本地大模型(LLM)。以前 16GB 的 PC 看起来已经能够处理所有任务,现在为了流畅运行 10B 以上参数的模型,32GB 甚至 64GB 逐渐成为新的门槛。这种需求叠加正在让内存紧缺进一步加剧。
前些天,硬盘存储的价格也同样遇到一波飙升。但最离谱的自然是显卡市场,逛了逛某二手交易平台,炙手可热的 RTX 4090 仍要近两万的价格。小编当年购入的 4090,在猛猛用了两年之后出手甚至还能挣钱…
内存涨价的行情不仅牵动着 GPU 厂商和消费者,也深刻影响到了科技公司,最近有消息称,谷歌的一些采购人员因为未能保证内存供应而遭解雇。
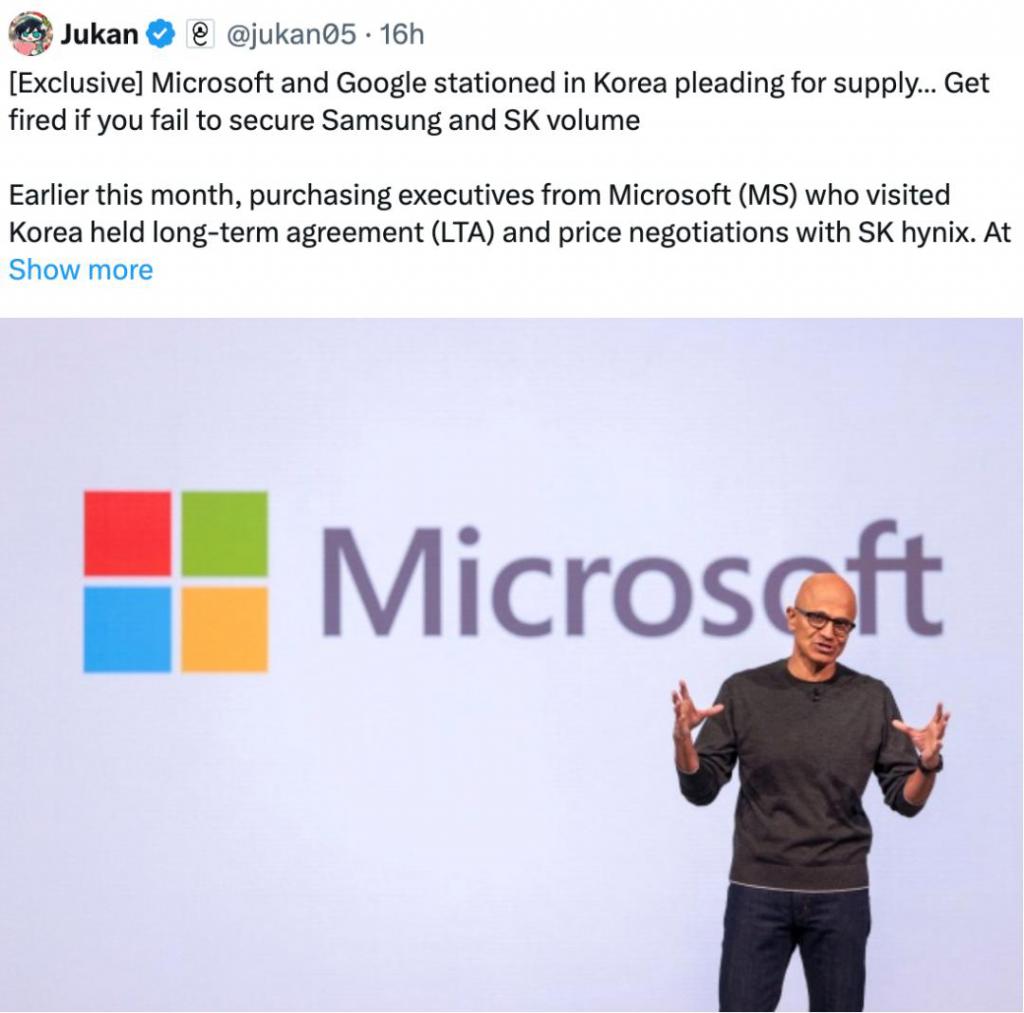
本月初,微软采购高管访问韩国,与 SK 海力士就长期供货协议及价格展开谈判。在会议中,SK 海力士明确表示:「在微软提出的条件下,供货存在困难。」一位半导体业内人士透露:「听到这个答复后,一名微软高管当场情绪失控,愤然离席。」
据产业界 25 日消息,随着全球 AI 半导体供应紧张局势加剧,包括微软、谷歌在内的全球科技巨头采购负责人正蜂拥至韩国,争抢产能。
半导体行业相关人士表示:「为了与三星电子和 SK 海力士签署存储器供货合同,微软、谷歌、Meta 等大型科技公司总部的采购负责人几乎是长期驻扎在韩国。」
目前,谷歌 TPU 所搭载的 HBM 中约 60% 由三星电子供应。随着近期 TPU 需求远超预期,谷歌试图向 SK 海力士与美光寻求追加产能,但得到的回复是:「不可能。」
据悉,谷歌管理层因此解雇了相关采购负责人,认为其未能提前签署长期供货协议,导致严重供应链风险,是对一线人员的问责性人事处分。
这些科技巨头为了内存供应而焦头烂额的时候,被认为是 AI 时代吃到最多红利的英伟达,同样也在为内存短缺烦恼。
尤其是在谷歌推出 TPU 芯片,向推理与规模化部署优先的战略转型,挑战英伟达在人工智能芯片的领先地位之后。
昨天,人工智能芯片初创公司 Groq 已与英伟达就推理技术达成了非排他性许可协议,同时英伟达挖走了 Groq 创始人兼 CEO Jonathan Ross、总裁 Sunny Madra 及多名核心工程师。详细信息可以参阅我们的报道。
Groq 的 LPU(Language Processing Unit)芯片未采用英伟达 GPU 常用的高带宽内存(HBM),而是将静态随机存取存储器(SRAM)直接集成在芯片内部。这种设计使单芯片内存带宽高达 80TB/s,是传统 HBM 方案的 20 倍以上。Groq 方案在物理空间和功耗上付出了代价:一个标准机架满载功耗约为 26kW 至 30kW,且需要比 GPU 方案更多的机架数量来承载同等规模的模型参数。
联系到疯涨的 HBM 内存价格,有业内人士提出了一种观点:
英伟达与 Groq 的交易,是为了对冲 DRAM 的价格疯涨和产能短缺,探索在内存上的新的技术路径。

Groq 在推理领域将一种设计哲学推向极端,核心赌注在于 SRAM。模型权重完全驻留在片上,并非作为缓存,而是作为主存储介质存在。
而 SRAM 的带宽比片外 HBM 高出若干个数量级,这一点至关重要,因为在推理过程中,每一个生成 token 的瓶颈受限于内存访问,而非浮点计算(FLOPs)。在此基础上,Groq 采用静态调度机制,计算与通信在编译阶段即被规划到时钟周期级别,从而消除了 GPU 架构时代大量存在的系统复杂性。
这场溢价接近 3 倍的收购,或许也是英伟达在「内存荒」的大背景下,正在开辟的第二条战线。
不过,对这部分说法也有不少反对意见,毕竟使用 SRAM 做主内存属实有些匪夷所思。
SRAM 之所以是 Mb 级别 而不是 Tb 级别,是因为 SRAM 非常快,但只有与逻辑电路集成在一起时才能发挥这一优势。换句话说,SRAM 的成本是在处理器芯片上制造高性能晶体管极其昂贵。英伟达的 Tensor Core 的芯片尺寸已经非常巨大,因此增加大量 SRAM 单元也会很快出现问题。
最后,对于我们这些普通消费者来说,是应该抓紧时间换机,还是等待这一波疯狂涨价过程的消退呢?
 晋ICP备17002471号-6
晋ICP备17002471号-6

 分享给我的好友
分享给我的好友