

俗话说得好,“三个臭皮匠、围殴诸葛亮”,如果在AI运算领域也能串联多座数据中心进行分布式运算的话,能带来什么效益呢?
NVIDIA将于2025年8月24至26日在美国斯坦福大学举办的Hot Chips 2025大会上进行许多重要议程,其中包含通过ConnectX-8 SuperNIC网络芯片串联机柜级与数据中心级运算单元,由Blackwell架构GeForce RTX 50系列显卡驱动的神经渲染绘图(Neural Rendering),硅光子共同封装交换机(Co-Packaged Optics Switches,CPO),GB10 Superchip与DGX Spark迷你超级计算机,NVLink Fusion应用等多个重要项目。
而在这次Hot Chips 2025中的重要消息之一,就是通过以太网络为基础串联多座数据中心的Spectrum-XGS Ethernet互联技术。它与先前NVLink、ConnectX等在单一机柜或数据中心范围应用的技术不同,Spectrum-X Ethernet能够做到跨数据中心串联,达到远程分布式运算的效果。
NVIDIA为这种技术概念称为Scale-Around,它能打破数据中心的距离限制,将不同地理位置的运算节点整合为单一超大型算节,除了能提高整体运算性能之外,也可以扩展可用内存容量,以容纳量体更大、参数更多的数据集或AI模型。
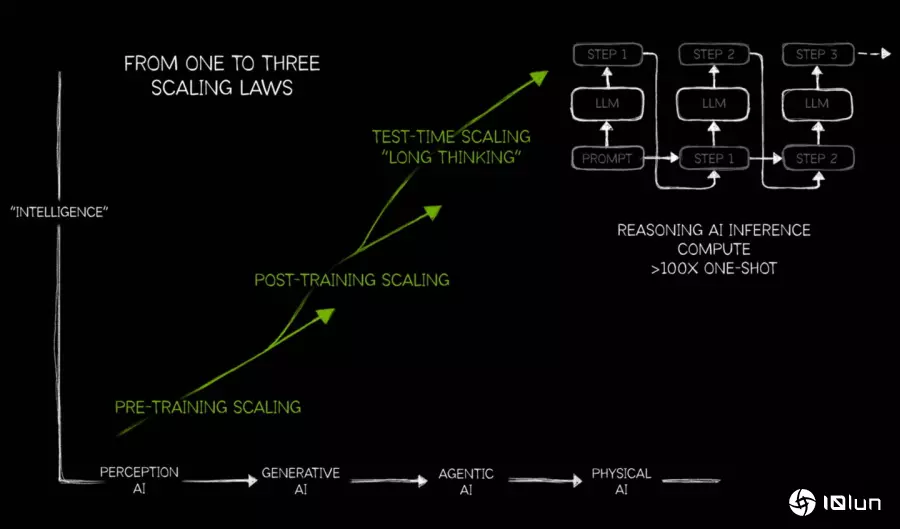 NVIDIA在说明会中提到,随着推理式与代理式AI的兴起,应用程序对AI运算性能的需求业随之增高。
NVIDIA在说明会中提到,随着推理式与代理式AI的兴起,应用程序对AI运算性能的需求业随之增高。
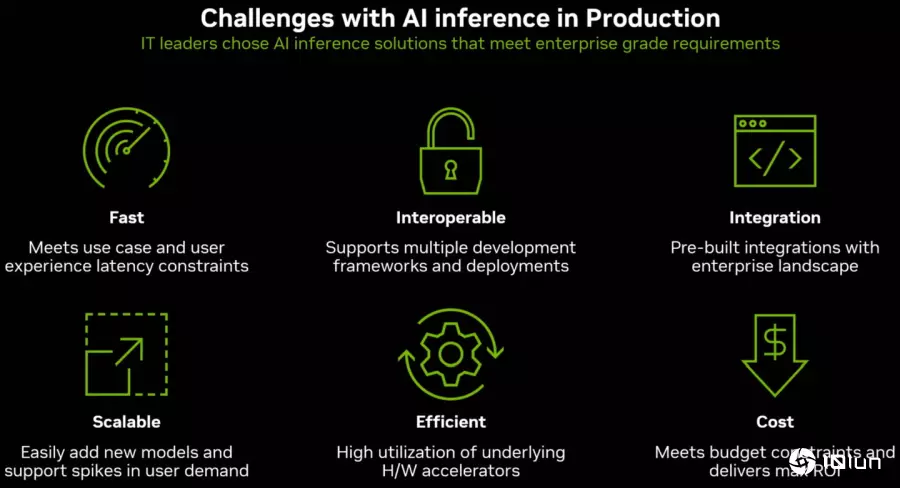 NVIDIA枚举速度、互通性、集成性、扩展性、效率、成本是AI推论的6大挑战。
NVIDIA枚举速度、互通性、集成性、扩展性、效率、成本是AI推论的6大挑战。
 NVIDIA将在Hot Chips 2025大会举办数据互联、神经渲染等多个主题的研讨议程。
NVIDIA将在Hot Chips 2025大会举办数据互联、神经渲染等多个主题的研讨议程。
 NVLink Fusion提供半定制化AI基础建设弹性,合作伙伴可以使用定制化处理器、网络界面、ASIC(特定应用集成电路)F搭配NVIDIA的GPU构建服务器与机柜。
NVLink Fusion提供半定制化AI基础建设弹性,合作伙伴可以使用定制化处理器、网络界面、ASIC(特定应用集成电路)F搭配NVIDIA的GPU构建服务器与机柜。
 NVFP4是使用4bit精度的数据类型,能够在AI训练与推论运算时节省计算资源与占用的内存容量、传输带宽,并提供接近BF16的精确度。
NVFP4是使用4bit精度的数据类型,能够在AI训练与推论运算时节省计算资源与占用的内存容量、传输带宽,并提供接近BF16的精确度。
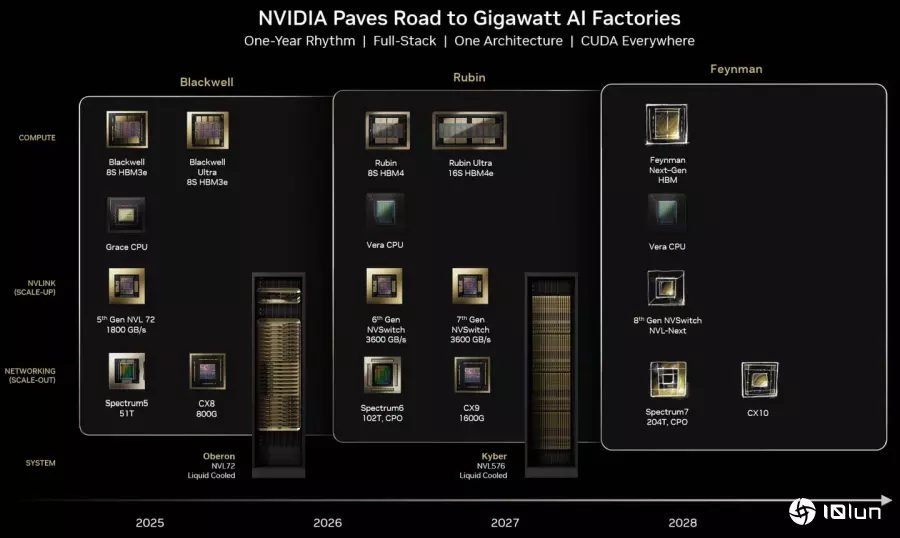 NVIDIA采用类似Tick-Tock的节奏更新产品,2025年推出Blackwell,2026年则推出强化版Blackwell Ultra,2027年推进至Rubin架构。
NVIDIA采用类似Tick-Tock的节奏更新产品,2025年推出Blackwell,2026年则推出强化版Blackwell Ultra,2027年推进至Rubin架构。
相较于提升单一运算节点性能的Scale-Up,或是串联运算多个节点以提高整体性能的Scale-Out(但各运算节点仍在同一数据中心内),Scale-Around的概念更着重于串联为于不同数据中心的远程运算节点,提供超低延迟、高带宽的数据交换渠道,能够编排(Orchestrating)多个数据中心的GPU对GPU(绘图处理器,能够加速AI运算)之间的庞大数据集的运算,将多座独立的数据中心集成为单一超级AI工厂,以满足超大量体(Giga-Scale)AI运算需求。
简单地说,Scale-Around就是打电话叫远方的兄弟赶来助阵,大家一起打群架的概念,通过集成多座数据中心的运算能力以带来更高的整体性能输出。
从理论上来看,Scale-Around概念由于数据传输距离较远,与Scale-Out相比一定会有延迟较高、带宽较低的缺点,但是它的优点则是能打破距离的隔阂,并且因多个数据中心为于不同地区,所以能舒缓单一电网供电的压力,并且可以灵活调度不同数据中心进行集成运算,可以视各数据中心的负载情况、时区(通长夜间负载较轻且电费较便宜)进行优化资源调度,具有更高的使用弹性。
NVIDIA说明Spectrum-XGS Ethernet是以Spectrum-X Ethernet平台为基础进化而来,NVIDIA创办人暨首席执行官黄仁勋表示,AI工业革命正在发生中,而规模更大的AI工厂是必要的基础建设,在Spectrum-XGS Ethernet的协助下,我们在现有的Scale-Up与Scale-Out之外导入创新的Scale-Around概念,将位于不同成市、国家、大陆的数据中心汇集为超大量体的超级AI工厂。
 不同于Scale-Up提升单一运算单元的性能,以及Scale-Out串联多个运算单元以提升单一节点的性能,NVIDIA提出全新的Scale-Around概念,通过网络串联多个数据中心的运算节点,进一步提升整体运算性能。
不同于Scale-Up提升单一运算单元的性能,以及Scale-Out串联多个运算单元以提升单一节点的性能,NVIDIA提出全新的Scale-Around概念,通过网络串联多个数据中心的运算节点,进一步提升整体运算性能。
关于更多Hot Chips 2025的资讯以及议程直播(需收费),可以参考Hot Chips官方网站。
 晋ICP备17002471号-6
晋ICP备17002471号-6

 分享给我的好友
分享给我的好友